En las previas notas del tema vimos las ventajas de usar Dividir columna del Power Query sobre la funcionalidad Texto en columnas del Excel clásico (y no será un exceso volver a enfatizar que, en todo lo relacionad con transformación de datos, Power Query es muy superior a Excel clásico).
Power Query es una herramienta en constante evolución. Microsoft ha incorporado últimamente cuatro nuevas opciones a Dividir columna a las "clásicas" Por delimitador y Por número de caracteres
Estas nuevas opciones facilitan aún más la tarea de extraer valores o dividir columnas. Veamos por ejemplo la siguiente situación: se nos pide extraer los valores numéricos de las celdas de la columna A
En la nota anterior comparamos Texto en columnas de Excel Clásico con Dividir Columna de Power Query para mostrar cuanto más eficiente es esta última herramienta.
En esta nota voy a mostrar una situación imposible de resolver cob Texto en Columnas y que Power Query lo hace con facilidad.
Consideremos esta tabla de clientes agrupados por vendedores
En otra tabla tenemos las ventas a cada cliente. Ahora supongamos que se nos pide calcular las comisiones de cada vendedor para lo cual tenemos que totalizar las ventas por vendedor. Obviamente los datos están organizados de manera tal que no podemos realizar la tarea. Necesitamos "aplanar" la tabla de tal manera que en cada fila haya una celda con el nombre del vendedor y la la celda contigua el nombre del cliente. De esa manera podremos usar Combinar consultas del Power Query para calcular las ventas por vendedor (o, si prefieran y espero que no lo prefieran, usar BUSCARV para extraer las ventas en cada fila y luego resumirlas con una tabla dinámica o SUMAR.SI).
Vamos a mostrar como hacerlo con Power Query es cuestión de segundos.
Una tarea frecuente cuando de transformar datos se trata es dividir una columna en varias. Desde sus primeras versiones Excel cuenta con una herramienta para dividir columnas: Texto en Columnas, denominación que nunca logré entender; "Dividir columna" (Split column) me parece más apropiado.
Pero no es éste el tema del post. Vamos a mostrar por que Dividir columna del Power Query es superior a Texto en Columnas del Excel clásico.
Veamos el siguiente caso. Hemos recibido una lista de clientes con una única columna que incluye el nombre del cliente, la dirección y la ciudad.
Nuestra tarea es extraer al ciudad de cada línea. Aparentemente Texto en columnas lo puede hacer con facilidad usando la coma como separador de los campos. Pero si nos fijamos con atención veremos que la fila 2 aparecen dos comas, una separa el nombre de la dirección y la otra la dirección de la ciudad, pero en la fila 3 hay tres comas (una precede el numero 23, la otra inmediatamente después del número).
Si usamos Texto en columnas obtendríamos ésto:
En algunos casos la ciudad aparece en la columna C y en otros en la columna D. Remediar esta situación en la hoja de Excel sería extenuante (supongamos una lista de cientos o tal vez miles de clientes).
Si usamos Power Query la tarea se convierte en "coser y cantar". Como siempre, empezamos por crear una conexión a la tabla
En el menú Inicio-Transformar abrimos las opciones de Dividir Columna-por delimitador
En el diálogo que se abre
Elegimos la opción Delimitador situado más a la derecha y apretamos Aceptar y ....
El nombre de la nueva columna lo establece Power Query. Podemos cambiarlo haciendo un doble clic sobre el encabezamiento o usando el menú contextual Cambiar nombre. También podemos editar el código del paso aplicado usando la barra de fórmulas
cambiando "Clientes.2" por el nombre deseado (digamos, Ciudad). Sencillamente lo editamos en la barra y apretamos Enter.
Ahora tenemos que separar el nombre del cliente de la dirección. Como ya habrán supuesto, usamos la opción Delimitador situado más a la izquierda.
En la nota anterior sobre el tema mostramos como comparar tablas con Power Query para encontrar, por ejemplo, diferencias entre ambas tablas. Por ejemplo, podemos comparar dos listas de nombres para controlar que nombres de las lista1 no aparecen en la lista2 o viceversa.
Todas las tareas las hicimos usando la interfaz del usuario. Es decir, sin necesidad de escribir o modificar ninguna línea de código para obtener el resultado. Sin embargo con cada paso que aplicamos, y que vemos reflejado en el panel de "Pasos Aplicados", Power Query está escribiendo líneas de código en su lenguaje, conocido como el lenguaje "M".
Voy a aprovechar esta nota para mostrar como podría comparar dos listas un usuario con ciertos conocimientos del lenguaje. Para lo cual voy a dedicar algunas líneas al lenguaje M.
El lenguaje M comprende objetos y funciones. Entre los objetos voy a mencionar las Tablas y las Listas. La diferencia entre una tabla y una lista, dicho en forma general, es que la lista siempre tendrá una sola columna. Así, por ejemplo, podemos tomar una columna de una tabla y convertirla en Lista y, a su vez, podemos convertir una lista en Tabla.
El motivo para estas transformaciones es que cada objeto, Listas y Tablas en nuestro caso, tiene su propia colección de funciones.
Power Query no tiene incorporado un asistente de funciones de manera que para consultar qué funciones existen tenemos que abrir está página (por ahora no se ha publicado una versión en castellano).
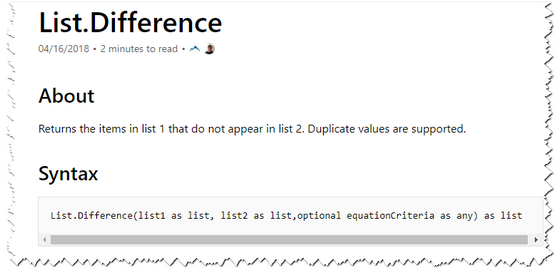
En nuestro ejemplo vamos a usar la función List.Difference. Las funciones están organizadas por categorías; la nuestra se encuentra en la categoría List Functions
Como vemos la función utiliza dos variables, las listas a comparar, y una tercera opcional que ignoraremos en esta nota.
"List" que antecede al nombre de la función nos indica que se trata de una que actúa sobre Listas. Esto quiere decir que para usarla tendremos que convertir, previamente, las columnas de nuestras tablas a listas.
Para evitar un tsunami de palabras en un largo post, voy a mostrar y explicar el proceso con este video
Ahora bien, si podemos hacer la comparación usando la interfaz de usuario, ¿por qué hacerlo escribiendo código?
La interfaz de usuario de Power Query es muy poderosa; nos permitirá resolver algo así como el 40% de nuestras necesidades de transformación de datos. Pero no todos los casos se pueden resolver sin escribir código o de la manera más eficiente.
Según Gil Raviv estas son las etapas del aprendizaje de Power Query y el lenguaje M
Solo interfaz - nos permite solucionar aproximadamente el 40% de los problemas.
Edición básica en la barra de fórmulas - Si bien no tenemos sólidos conocimientos de M y las funciones, si podemos asociar elementos en las fórmulas con las pasos dados con la interfaz y lograr ciertas transformaciones. En esta etapa ya podemos resolver el 60% de los problemas.
M en columnas personalizadas - En esta etapa dominamos el uso de columnas personalizadas y podemos crear fórmulas efectivas; dominamos el uso de condicionales y los operadores Booleanos. En esta etapa ya nos enfrentamos con éxito al 80% de los problemas.
Funciones personalizadas - En esta etapa ya dominamos el uso de funciones personalizadas lo que nos permite reusar transformaciones que hemos creado. Ahora ya podemos resolver el 95% de los problemas.
Iteraciones avanzadas - En esta etapa ya sabemos enfrentarnos a escenarios complejos y es cuando empezamos a usar funciones como List.Accumulate y List.Generate para crear iteraciones de transformaciones. Ya sabemos resolver el 99% de los desafíos que nos presenten; el 1% restante pueden ser resueltos usando otras herramientas.
Gil describe una sexta etapa sobre la cual no me voy a extender ya que está reservada a los super-humanos (o Cyborgs o seres de otras galaxias).
Para los simples mortales un buen punto de comienzo es el curso de Ivan Pinar Dominguez
En la serie de notas sobre el tema vimos que usamos "Combinación de tablas" para buscar y extraer datos extraer datos de una tabla a otra, lo que en el Excel "clásico" hacemos con la función BUSCARV (o con una combinación de INDICE y COINCIDIR).
En esta nota vamos a considerar otra posibilidad que nos ofrece la combinación de tablas en Power Query: comparar tablas.
A los efectos del ejemplo supongamos que queremos comparar dos tablas que contienen ventas de determinados productos, una contiene las ventas del año 2017 y la otra las del año 2018.
Nuestro jefe nos pide realzar las siguientes comparaciones:
que productos se vendieron en el 2018 y no se vendieron en el 2017;
que productos se vendieron en el 2017 y no en el 2018;
que productos se vendieron en ambos años.
Empezamos por crear una consulta a cada tabla de datos
Las tablas de origen pueden estar en una base de datos, en un cuaderno de Excel o cualquier otro tipo de fuente. Al crear las consultas, también de fuentes remotas, como "solo conexión" evitamos duplicar datos (que ya existen en la fuente de origen) lo que nos ayuda a evitar problemas generados por redundancia de datos:
falta de sincronizado (cambios en el origen siempre se reflejan en los conexiones);
archivos innecesariamente "pesados".
Cuando combinamos datos entre dos tablas Power Query nos ofrece distintos modos de hacer la combinación, como podemos ver en el asistente de Combinación de tablas
Básicamente tres tipos de combinación: Externa (derecha, izquierda, completa); Interna y Anti (izquierda, derecha). Las descripciones que aparecen entre paréntesis describen la tarea de cada uno de los tipos. Las descripciones del tipo Anti no son lo suficientemente claras, para mi gusto. En "Anti izquierda dice "solo filas de la primera"; debería decir "sólo filas presentes en la primer tablas y no en la segunda". Lo mismo para "Anti derecha": "sólo filas presentes en la segunda tabla y no en la primera".
Para los ejemplos de esta nota vamos a usar los tres últimos tipos: Interna, Anti izquierda y Anti derecha.
Empecemos por el primer pedido de nuestro jefe:
Productos vendidos en el 2018 y sin ventas en el 2017
Apuntamos con el mouse a la consulta "2017", con un clic derecho abrimos el menú contextual y elegimos la opción Combinar
Esto abre el editor de consultas. En el diálogo de la combinación de tablas vemos que "2017" aparece como primera tabla, agregamos"2018" como segunda, seleccionamos el campo Producto en ambas tablas y elegimos el tipo de combinación "Anti derecha"
Apretamos aceptar y veremos esto
La tabla "2018" ha sido agregada como columna con la doble flecha a la derecha del encabezamiento, ésto nos indica que podemos expandir la columna (de hecho, la tabla) y elegir qué campos queremos agrega
.
En nuestro ejemplo elegimos solamente "Producto" para ver que productos aparecen en las ventas de 2018 y no en la de 2017
Podemos ver que las columnas de la tabla 2017 contienen el valor "null", ya que los productos de la columna "2018.Producto" no tienen equivalente en el 2017. Ahora podemos eliminar las columnas de la tabla 2017 y cambiar el encabezamiento de "2018.Producto" por algo más descriptivo como "Productos vendidos en 2018 y no en 2017" y cargar la tabla en la hoja
Ahora debemos encarar la segunda tarea:
Productos se vendieron en el 2017 y no en el 2018
Podemos repetir el proceso anterior cambiando el orden de combinación de las tablas con el mismo tipo de combinación (Anti derecha) o dejando el orden y cambiando el tipo de combinación a Anti izquierda.
Pero como soy un tanto holgazán voy a usar un atajo (a pesar de las sabias enseñanzas de mi abuelita: "Si los atajos fueran buenos no habría caminos").
Vamos a duplicar la consulta que acabamos de crear (Merge1)
Al duplicar obtenemos una nueva consulta idéntica a la de origen. Lo que haremos es modificar uno de los pasos aplicados. La consulta duplicada se abre en el editor de PQ y veremos el resultado de la consulta anterior. En el panel de pasos aplicados hacemos un clic al engranaje que aparece a la derecha del paso aplicado "Origen". Esto abrirá el diálogo de combinación de tablas
El la casilla "Tipo de combinación" cambiamos el tipo a "Anti izquierda"
y apretamos "Aceptar"
Al expandir la columna para ver los productos de la tabla 2018, veremos que el resultado es "null" (nulo, no hay coincidencias).
Ahora tenemos que borrar los próximos dos pasos en el panel Pasos Aplicados y aplicar los correspondientes: cambiar el nombre de la columna "Productos" a "Productos vendidos en 2017 y no en 2018" y eliminar el resto de las columnas.
Ahora nos ocuparemos de la última tarea:
Productos se vendieron en ambos años
Obviamente vamos a utilizar el tipo de combinación "Interna" que nos traerá las filas donde el producto coincide en ambas tablas
Creamos una consulta combinando las tablas 2017 y 2018 y elegimos el tipo de combinación Interna
Al pie del formulario Power Query nos informa el resultado: 68 productos.
Para terminar nuestra tarea eliminamos todas las columnas excepto "Producto", cambiamos el encabezamiento a algo como "Productos vendidos en 2017 y 2018" y la cargamos a una hoja. De hecho, podemos cargar todas las consultas en una misma hoja
En este ejemplo nos hemos limitado a comparar los productos, pero el informe podría contener también los datos de ventas, por ejemplo, y en el informe de los productos vendidos en ambos años una comparación de las ventas.
Y recordemos, una vez desarrollado nuestro modelo, cada vez que actualicemos los datos de origen un simple clic a "Datos - actualizar todo" actualiza el informe en cuestión de segundos.
En su comentario a la tercera nota de la serie me preguntaba el lector Alfredo cómo haríamos si queremos mostrar todos los resultado. Es decir, filtrar sólo por el nombre del producto.
Obviamente tenemos que crear una condición de manera que si la celda F2 (Orden_de_aparición) esta en blanco no se aplique el filtro (y caso contrario si aplicarlo).
En todas las notas de la serie hemos hecho las transformaciones usando la interfaz de usuario, es decir, sin tener que escribir código por nuestros propios medios.
Power Query nos permite solucionar, por lo menos, el 80% de nuestros problemas de transformación de datos directamente a través de la interfaz de usuario. Esto significa que no necesitamos conocer el lenguaje M y escribir código por nuestra cuenta para solucionar problemas de manejo de datos.
En el caso que nos consulta Alfredo si tendremos que agregar una línea de código. Si bien esto supone ya conocimientos más avanzados, también el usuario principiante o intermedio se beneficiará descubriendo las increíbles posibilidades que nos ofrece Power Query.
En el modelo de la nota anterior introducíamos el nombre del producto en la celda F1 (que habíamos ligado al nombre definido "Producto") y el orden de aparición buscado en la celda F2 (asimismo ligada al nombre definido "Orden_de_aparición"). Al activar "Datos-Actualizar todo", obteníamos el resultado en la celda E6. Si dejamos la celda F2 en blanco, la celda E6 también quedará en blanco. Esto quiere decir que cuando Power Query no encuentra el orden de aparición buscado, el resultado es "null".
Cuando aplicamos pasos en el editor Power Query va generando el código correspondiente a esos pasos
Para crear la posibilidad de mostrar todas las filas del producto en el caso de dejar en blanco la celda F2 (Orden_de_aparición) tendremos que intervenir en el anteúltimo paso ("Filas filtradas1"). Veamos el código creado por Power Query para hacer el filtrado; podemos verlo en la barra de las fórmulas
o en el editor avanzado
En el editor avanzado reemplazamos el paso #"Filas filtradas1" por el siguiente código:
#"Filas filtradas1" = if Orden_de_aparición<>null then Table.SelectRows(#"Índice agregado", each ([Índice] = Orden_de_aparición)) else #"Índice agregado",
(para facilitar la lectura dividimos el código en varias líneas apretando Enter; de la misma manera podríamos escribir el código en una sola línea).
Como pueden ver estamos creando una condición: Si (if) el valor del parámetro Orden_de_aparición no es "null" (vacío) entonces aplicamos la función Table.SelectRows; en caso contrario (else) nos referimos al paso anterior (#"Índice agregado") sin tomar ninguna acción, que es la forma de ignorar el filtrado.
En nuestro ejemplo si dejamos la celda F2 vacía
tendremos este resutlado
y al cargar la consulta en la hoja y apretar "Datos-Actualizar todo" veremos
Comencé a publicar notas en este blog en el año 2006 a sugerencia de un compañero de trabajo. Todo el tiempo te consultan, me decía, ¿no te sería más práctico publicar las respuestas en un sitio o blog?
Considerando la propuesta dediqué unos días a leer los distintos blogs y sitios sobre Excel que habitaban en esa época el espacio WWW. Mi primera conclusión fue que no había nada que yo pudiera agregar a lo ya publicado, en particular en inglés pero también en castellano. Hasta que encontré la siguiente frase: "No importa cuán bueno seas, siempre habrá uno mejor que ti". Despojado del deseo, oculto pero deseo al fin, de ser el mejor comencé a publicar con la meta de compartir mis experiencias como usuario de Excel y ayudar a otros a avanzar en el uso de esta herramienta.
En setiembre del 2017, once años y 745 posts más tarde llegué al punto donde consideré cumplido mi ciclo.
Sin embargo, aquí estoy nuevamente, publicando y dialogando con mis lectores poco menos de dos años después de mi "retiro". ¿Que ha pasado?
En los últimos años Microsoft ha sumado nuevas herramientas a Excel: Tablas ("Listas" en Excel 2003), Power Query y Power Pivot.
Esta nuevas herramientas han revolucionado la forma en que debemos trabajar con Excel. No menos que la introducción de las tablas dinámicas o del Vba.
Y pongo el acento en "debemos" porque para aprovechar estas herramientas deberemos dejar viejos hábitos y entender cabalmente cual es la mejor práctica de trabajo con el nuevo Excel. Y este es el motivo que me ha llevado a renovar mi actividad en el blog: propagar el uso de esta nuevas herramientas y las buenas prácticas en la transformación y manejo de datos en Excel.
En las notas anteriores vimos como usar Power Query en lugar de BUSCARV cuando el orden de las columnas nos obliga en la tabla de referencia nos obliga a realizar la búsqueda derecha a izquierda y cuando debemos realizar la búsqueda en base a dos o más criterios.
También mencioné al pasar otra ventaja. Power Query nos permite realizar transformaciones y manejar datos sin alterar los datos originales. Sobre este tema, que es una de las ventajas cardinales de usar Power Query, me extenderé en una futura nota.
En esta nota veremos como resolver la situación en la que la tabla de búsqueda contiene valores repetidos. Por definición BUSCARV dará como resultado el valor de la primera coincidencia e ignorará los restantes (situación natural ya que una celda de Excel sólo puede contener un único valor).
Cuando usamos BUSCARV para extraer un valor de una tabla y ésta contiene valores repetidos, debemos preguntarnos qué valor queremos extraer. El primero, de acuerdo al orden de la tabla, lo obtendremos por definición. Pero si queremos extraer el mayor o el menor o el segundo, etc., ¿cómo haremos?.
Vamos a volver al ejemplo de la nota que publiqué en el mes de julio del 2008 (BUSCARV en listas con valores repetdios). En ese ejemplo cada elemento de la tabla se repetía tres veces.
El desafío era extraer el precio del producto Tornillos que aparece en segundo lugar. Usando BUSCARV obtendríamos 7.65 ya que este es el primero en aparecer en la tabla; el resultado esperado es 9.74. En la nota del 2008 lo resolvimos usando una fórmula matricial de 203 caracteres de largo (!!). Once años más tarde tenemos, por suerte, el Power Query.
Vamos a empezar por asignar una celda para el producto buscado y otra para el orden de aparición del precio. A ambas celdas le asignamos un nombre definido
Podemos ver que el nombre definido "Orden_de_aparición" se refiere a la celda F2 y el nombre "Producto" a la celda F1.
Nuestro segundo paso es crear una consulta a la tabla de productos que guardamos como "solo conexión" (ver la primer nota de la serie)
Ahora haremos algo similar con los nombres definidos, pero con una pequeña "vuelta de tuerca". Seleccionamos la celda F1 y creamos una consulta usando "Obtener datos - Desde tabla o rango". Al abrirse la consulta en el editor de Power Query veremos en el panel de Pasos Aplicados, que PQ ha creado automáticamente dos pasos además de "Origen"
Eliminamos todos los pasos aplicados excepto "Origen" usando la X a la izquierda del nombre o haciendo un clic derecho sobre el nombre del paso y usando Eliminar. Este será el resultado
Ahora apuntamos con el mouse a la celda (en realidad es un registro, no una celdas pero valga la licencia "exceliana"), clic derecho y aplicamos "drill down" (Rastrear desagrupando datos en la lengua de Cervantes, según Microsoft)
con este resultado
Ahora vamos a "Inicio - Cerrar y Cargar en" y seleccionamos la opción "Crear sólo conexión".
Repetimos la operación con la celda F2.
En el panel de consultas veremos, además de la conexión a la Tabla1, las dos conexiones que acabamos de crear
De hecho hemos creado dos parámetros, como lo indica el ícono a la izquierda de la consulta.
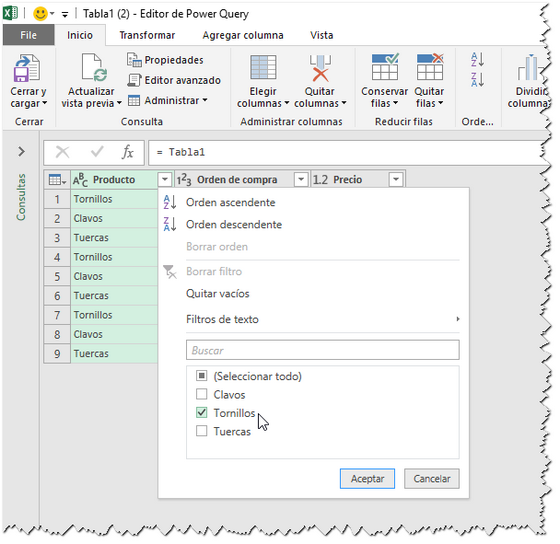
En el próximo paso abrimos la consulta Tabla1 en el editor y aplicamos el filtro a la columna Producto con el valor Tornillo
Esto es similar al Autofiltro de Excel. Apretamos "Aceptar"
Prestemos atención al panel de las fórmulas
Podemos ver que PQ aplica la función Table.SelectRows con el valor fijo "Tornillos". Nosotros queremos que la consulta sea dinámica, es decir, que cuando cambiemos el nombre del producto en la celda F1 también la consulta cambie. Para eso vamos a reemplazar el valor "Tornillos" en la fórmula con el nombre de la consulta/parámetro "Producto" que creamos previamente
Prestemos atención que introducimos Producto sin las comillas (de hacerlo con las comillas PQ lo interpretaría como valor fijo, no como parámetro).
El próximo paso es agregar una columna con el número de orden de cada fila. Esto lo hacemos con facilidad usando "Agregar columna-Columna de índice-Desde 1"
Ahora filtramos la columna "Indice" dejando el valor 2, que luego, como ya han adivinado, reemplazaremos en la fórmula por el parámetro "Orden_de_aparición"
Finalmente eliminamos todas las columnas menos "Precio"
y aplicamos "Cerrar y cargar". Como previamente guardamos la consulta como "Solo crear conexión" no podemos en este paso cambiar el destino del resultado. Para hacerlo usamos el menú contextual (clic derecho sobre la consulta)
y en e diálogo que se abre elegimos la celda de destino
¡Voila!
Llego el momento de comprobar que nuestro modelo es realmente dinámico. Cambiamos los valores en F1 y F2, por ejemplo a Clavos y 3, y apretamos "Datos-Actualizar Todo"