Todas las tareas las hicimos usando la interfaz del usuario. Es decir, sin necesidad de escribir o modificar ninguna línea de código para obtener el resultado. Sin embargo con cada paso que aplicamos, y que vemos reflejado en el panel de "Pasos Aplicados", Power Query está escribiendo líneas de código en su lenguaje, conocido como el lenguaje "M".
Voy a aprovechar esta nota para mostrar como podría comparar dos listas un usuario con ciertos conocimientos del lenguaje. Para lo cual voy a dedicar algunas líneas al lenguaje M.
El lenguaje M comprende objetos y funciones. Entre los objetos voy a mencionar las Tablas y las Listas. La diferencia entre una tabla y una lista, dicho en forma general, es que la lista siempre tendrá una sola columna. Así, por ejemplo, podemos tomar una columna de una tabla y convertirla en Lista y, a su vez, podemos convertir una lista en Tabla.
El motivo para estas transformaciones es que cada objeto, Listas y Tablas en nuestro caso, tiene su propia colección de funciones.
Power Query no tiene incorporado un asistente de funciones de manera que para consultar qué funciones existen tenemos que abrir está página (por ahora no se ha publicado una versión en castellano).
En nuestro ejemplo vamos a usar la función List.Difference. Las funciones están organizadas por categorías; la nuestra se encuentra en la categoría List Functions
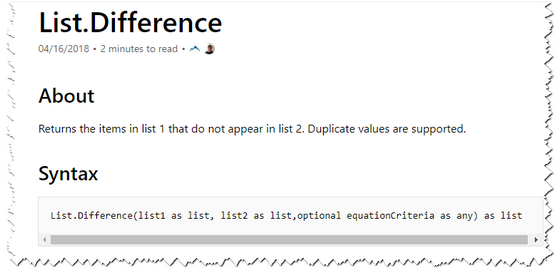
Como vemos la función utiliza dos variables, las listas a comparar, y una tercera opcional que ignoraremos en esta nota.
"List" que antecede al nombre de la función nos indica que se trata de una que actúa sobre Listas. Esto quiere decir que para usarla tendremos que convertir, previamente, las columnas de nuestras tablas a listas.
Para evitar un tsunami de palabras en un largo post, voy a mostrar y explicar el proceso con este video
Ahora bien, si podemos hacer la comparación usando la interfaz de usuario, ¿por qué hacerlo escribiendo código?
La interfaz de usuario de Power Query es muy poderosa; nos permitirá resolver algo así como el 40% de nuestras necesidades de transformación de datos. Pero no todos los casos se pueden resolver sin escribir código o de la manera más eficiente.
- Solo interfaz - nos permite solucionar aproximadamente el 40% de los problemas.
- Edición básica en la barra de fórmulas - Si bien no tenemos sólidos conocimientos de M y las funciones, si podemos asociar elementos en las fórmulas con las pasos dados con la interfaz y lograr ciertas transformaciones. En esta etapa ya podemos resolver el 60% de los problemas.
- M en columnas personalizadas - En esta etapa dominamos el uso de columnas personalizadas y podemos crear fórmulas efectivas; dominamos el uso de condicionales y los operadores Booleanos. En esta etapa ya nos enfrentamos con éxito al 80% de los problemas.
- Funciones personalizadas - En esta etapa ya dominamos el uso de funciones personalizadas lo que nos permite reusar transformaciones que hemos creado. Ahora ya podemos resolver el 95% de los problemas.
- Iteraciones avanzadas - En esta etapa ya sabemos enfrentarnos a escenarios complejos y es cuando empezamos a usar funciones como List.Accumulate y List.Generate para crear iteraciones de transformaciones. Ya sabemos resolver el 99% de los desafíos que nos presenten; el 1% restante pueden ser resueltos usando otras herramientas.
Gil describe una sexta etapa sobre la cual no me voy a extender ya que está reservada a los super-humanos (o Cyborgs o seres de otras galaxias).
Para los simples mortales un buen punto de comienzo es el curso de Ivan Pinar Dominguez

Para los simples mortales un buen punto de comienzo es el curso de Ivan Pinar Dominguez























